นี่เป็นส่วนที่ 2 ของชุด Scikit-learn ซึ่งมีดังต่อไปนี้
- ส่วนที่ 1 — บทนำ
- ส่วนที่ 2 — การเรียนรู้ภายใต้การดูแลใน Scikit-Learn (บทความนี้)
- ส่วนที่ 3 — การเรียนรู้แบบไม่มีผู้ดูแลใน Scikit-Learn
ลิงก์ไปยังส่วนที่หนึ่ง : https://medium.com/@deepanshugaur1998/scikit-learn-part-1-introduction-fa05b19b76f1
ลิงก์ไปยังส่วนที่สาม : https://medium.com/@deepanshugaur1998/scikit-learn-beginners-part-3-6fb05798acb1
การเรียนรู้ภายใต้การดูแลใน Scikit-Learn
สวัสดีอีกครั้ง !
สรุปการเรียนรู้แบบมีผู้สอน:

ถามการเรียนรู้แบบมีผู้สอนคืออะไร?
ในการเรียนรู้ของเครื่อง มันเป็นระบบประเภทหนึ่งที่มีการให้ข้อมูลทั้งอินพุตและเอาต์พุตที่ต้องการ ข้อมูลอินพุตและเอาต์พุตมีป้ายกำกับสำหรับการจำแนกประเภทเพื่อเป็นพื้นฐานการเรียนรู้สำหรับการทำนายข้อมูลในอนาคต

เช่นเดียวกับในส่วนที่แล้วของซีรีส์นี้ เราได้เห็นภาพรวมของสิ่งที่ scikit เรียนรู้แล้วในแง่ของการเรียนรู้แบบมีผู้สอน แต่ในส่วนนี้ เราจะเข้าใจว่าเราจะเริ่มต้นใช้งานห้องสมุดอันทรงพลังนี้ได้อย่างไร
เริ่มต้นใช้งาน…..
ลองพิจารณาตัวอย่างแบบจำลองการถดถอยเชิงเส้นอย่างง่าย :
จุดมุ่งหมายทางคณิตศาสตร์ของแบบจำลองนี้คือเพื่อลดผลรวมที่เหลือของกำลังสองระหว่างการตอบสนองที่สังเกตได้ในชุดข้อมูล และผลลัพธ์ที่ทำนายได้โดยการประมาณเชิงเส้น

from sklearn.linear_model import LinearRegression #import statement clf=LinearRegression() #we created a classifier from an object named LinearRegression. clf.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2]) #fitting a classifier on a data clf.coef_ # calculated the slope OUTPUT : array([ 0.5, 0.5])
อย่างที่คุณเห็น มีเพียงโค้ดเล็กๆ น้อยๆ ที่สามารถช่วยให้คุณเริ่มต้นกับอัลกอริธึมที่น่าทึ่งนี้ได้ มันไม่น่าทึ่งเหรอ? คุณยังสามารถลองทำนายชุดการทดสอบได้โดยใช้ฟังก์ชัน '.pred'
หากต้องการทำความเข้าใจเชิงลึกเพิ่มเติมเกี่ยวกับโมเดลเชิงเส้นนี้ ให้ลองใช้ตัวอย่างด้วยตนเอง
ดูตัวอย่างง่ายๆ ได้ที่นี่ :
รองรับเครื่องเวกเตอร์ใน Sklearn
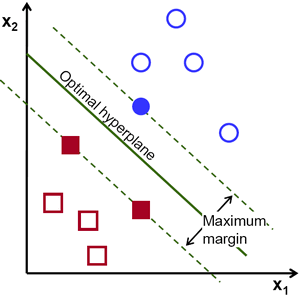
ทำตามโค้ดด้านล่างเพื่อเริ่มต้นใช้งาน svm ใน scikit-learn :
from sklearn import svm X = [[0, 0], [1, 1]] # dataset y = [0, 1] clf = svm.SVC() # classifier is created clf.fit(X, y) # fitting classifier on dataset OUTPUT : SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
พารามิเตอร์ที่คุณเห็นในวงเล็บสามารถเปลี่ยนแปลงได้ตามชุดข้อมูลที่คุณได้รับ
เมื่อคุณรู้สึกสบายใจที่จะเขียนโค้ดที่กล่าวถึงข้างต้นแล้ว ให้ลองปรับแต่งพารามิเตอร์ด้วยตนเอง< /แข็งแกร่ง>
clf.predict([[1., 0.]]) # predicting values OUTPUT : array([1])
การไล่ระดับสีแบบสุ่มใน Sklearn

อัลกอริธึม Stochastic Gradient Descent เป็นอัลกอริธึมง่ายๆ ที่ใช้ในการเรียนรู้แบบจำแนกประเภทของตัวแยกประเภทเชิงเส้นบนชุดข้อมูลขนาดใหญ่ และยังปรับให้เข้ากับมันได้อย่างง่ายดาย
รหัส :
from sklearn.linear_model import SGDClassifier
X = [[0., 0.], [1., 1.]]
y = [0, 1]
clf = SGDClassifier(loss=”hinge”, penalty=”l2") #hyperparameters
clf.fit(X, y)
OUTPUT : SGDClassifier(alpha=0.0001, average=False, class_weight=None, epsilon=0.1,
eta0=0.0, fit_intercept=True, l1_ratio=0.15,
learning_rate='optimal', loss='hinge', max_iter=5, n_iter=None,
n_jobs=1, penalty='l2', power_t=0.5, random_state=None,
shuffle=True, tol=None, verbose=0, warm_start=False)
ไร้เดียงสา Bayes ใน Sklearn

ตัวแยกประเภท Naive Bayes คำนวณความน่าจะเป็นสำหรับทุกปัจจัย จากนั้นจะเลือกผลลัพธ์ที่มีความน่าจะเป็นสูงสุด
ตัวแยกประเภทนี้ถือว่าคุณลักษณะต่างๆ มีความเป็นอิสระ ดังนั้นจึงมีการใช้คำว่า "ไร้เดียงสา"
เป็นหนึ่งในอัลกอริธึมที่พบบ่อยที่สุดในแมชชีนเลิร์นนิง
รหัส :
from sklearn import datasets iris = datasets.load_iris() # loading the dataset from sklearn.naive_bayes import GaussianNB gnb = GaussianNB() y_pred = gnb.fit(iris.data, iris.target).predict(iris.data) #fitting and predicting on same line. OUTPUT : [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
การถดถอยแบบต้นไม้การตัดสินใจใน Sklearn

Decision Trees เป็นอัลกอริธึม Machine Learning แบบมีผู้ดูแลอีกประเภทหนึ่ง โดยที่ข้อมูลจะถูกแบ่งอย่างต่อเนื่องตามพารามิเตอร์บางตัว
ข้อมูลเพิ่มเติมยิ่งมากคือความแม่นยำของโมเดล
Decision Trees เป็นหนึ่งในอัลกอริธึมที่ใช้มากที่สุด จากอัลกอริธึมการเรียนรู้ภายใต้การดูแลทั้งหมดและค้นหาแอปพลิเคชันขนาดใหญ่ในอุตสาหกรรม

รหัส :
from sklearn import tree X = [[0, 0], [1, 1]] Y = [0, 1] clf = tree.DecisionTreeClassifier() clf = clf.fit(X, Y) clf.predict([[2., 3.]]) OUTPUT : array([1])
วิธีการรวมกลุ่มใน SkLearn
มีวิธีการบรรจุถุงและป่าสุ่ม
ป่าสุ่ม

อัลกอริธึมการเรียนรู้ของเครื่องอันทรงพลังอีกตัวหนึ่งที่สร้างผลลัพธ์ที่ยอดเยี่ยมแม้จะไม่มีการปรับแต่งไฮเปอร์พารามิเตอร์ก็ตาม
นอกจากนี้ยังเป็นหนึ่งในอัลกอริธึมที่ใช้มากที่สุด เนื่องจากความเรียบง่ายและสามารถใช้ได้กับทั้งงานจำแนกประเภทและงานการถดถอย
Code :
from sklearn.ensemble import RandomForestClassifier X = [[0, 0], [1, 1]] Y = [0, 1] clf = RandomForestClassifier(n_estimators=10) clf = clf.fit(X, Y) pred = clf.predict([[2., 3.]]) print(pred) OUTPUT : [1]
เราได้เรียนรู้อะไรบ้าง?
ตอนนี้เราได้เรียนรู้วิธีการใช้อัลกอริธึมภายใต้การดูแลแต่ละอันโดยใช้ scikit learn แล้ว
ยังมีฟีเจอร์มากมายที่แต่ละอัลกอริทึมมีใน scikit learn ซึ่งสามารถเชี่ยวชาญได้โดยการฝึกฝนเท่านั้น
ดังนั้นหยุดเสียเวลาและหัวของคุณซะ ตรงไปยังเอกสารประกอบอย่างเป็นทางการของ scikit เรียนรู้สำหรับอัลกอริธึมภายใต้การดูแล และให้แน่ใจว่าคุณเข้าใจอัลกอริธึมแต่ละอันในเชิงคณิตศาสตร์ เช่นเดียวกับการฝึกฝนกับชุดข้อมูลที่แตกต่างกัน
ลิงก์ :
http://scikit-learn.org/stable /supervised_learning.html
หมายเหตุ: ส่วนถัดไปของซีรีส์นี้จะเป็นการเรียนรู้แบบไม่มีผู้ดูแล ดังนั้นอย่าพลาด