เราจะให้คำนิยามมันอย่างไร
การถดถอยเชิงเส้นเป็นการวิเคราะห์ทางสถิติประเภทหนึ่งที่ใช้ในการทำนายความสัมพันธ์ระหว่างตัวแปรสองตัว โดยถือว่าความสัมพันธ์เชิงเส้นระหว่างตัวแปรอิสระและตัวแปรตาม และมุ่งหวังที่จะค้นหาเส้นที่เหมาะสมที่สุดที่อธิบายความสัมพันธ์
การถดถอยเชิงเส้นมักใช้ในหลายสาขา รวมถึงเศรษฐศาสตร์ การเงิน และสังคมศาสตร์ เพื่อวิเคราะห์และทำนายแนวโน้มของข้อมูล
การถดถอยเชิงเส้นอย่างง่าย
ในการถดถอยเชิงเส้นอย่างง่าย จะมีตัวแปรอิสระหนึ่งตัวและตัวแปรตามหนึ่งตัว แบบจำลองจะประมาณความชันและจุดตัดของเส้นที่เหมาะสมที่สุด ซึ่งแสดงถึงความสัมพันธ์ระหว่างตัวแปร ความชันแสดงถึงการเปลี่ยนแปลงในตัวแปรตามสำหรับการเปลี่ยนแปลงแต่ละหน่วยในตัวแปรอิสระ ในขณะที่จุดตัดแสดงค่าที่ทำนายไว้ของตัวแปรตามเมื่อตัวแปรอิสระเป็นศูนย์
การถดถอยเชิงเส้นแสดงความสัมพันธ์เชิงเส้นระหว่างตัวแปรอิสระ (ตัวทำนาย) เช่น แกน X และตัวแปรตาม (เอาต์พุต) เช่น แกน Y เรียกว่าการถดถอยเชิงเส้น หากมีตัวแปรอินพุตตัวเดียว X(ตัวแปรอิสระ) การถดถอยเชิงเส้นดังกล่าวเรียกว่า การถดถอยเชิงเส้นอย่างง่าย

จะคำนวณเส้นที่เหมาะสมที่สุดได้อย่างไร?
ในการคำนวณการถดถอยเชิงเส้นเส้นตรงที่เหมาะสมที่สุด ให้ใช้รูปแบบจุดตัดความชันแบบดั้งเดิมซึ่งแสดงไว้ด้านล่าง
Yi = β0 + β1*Xi
โดยที่ Yi = ตัวแปรตาม, β0 = ค่าคงที่/จุดตัด, β1 = ความชัน/จุดตัด, Xi = ตัวแปรอิสระ
อัลกอริธึมนี้อธิบายความสัมพันธ์เชิงเส้นระหว่างตัวแปรตาม (เอาต์พุต) y และตัวแปรอิสระ (ตัวทำนาย) X โดยใช้เส้นตรง Y= B0 + B1* X
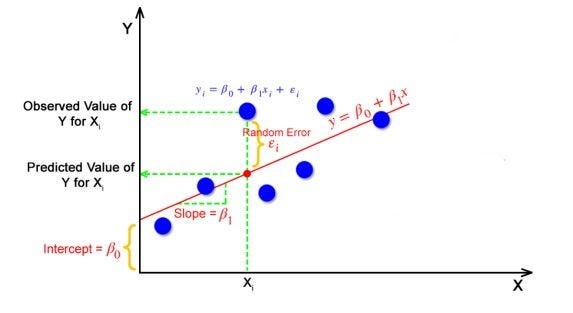
ในการถดถอย ความแตกต่างระหว่างค่าที่สังเกตได้ของตัวแปรตาม (Yi) และค่าที่ทำนาย (ทำนาย) เรียกว่าค่าคงเหลือ
εi = คาดการณ์ — Yi
โดยที่ Y คาดการณ์ = B0 + B1*Xi
ฟังก์ชันต้นทุนสำหรับการถดถอยเชิงเส้น
ฟังก์ชันต้นทุน ช่วยในการคำนวณค่าที่เหมาะสมที่สุดสำหรับ B0 และ B1 ซึ่งให้เส้นที่เหมาะสมที่สุดสำหรับจุดข้อมูล
ในการถดถอยเชิงเส้น โดยทั่วไปจะใช้ฟังก์ชันต้นทุน Mean Squared Error (MSE) ซึ่งเป็นค่าเฉลี่ยของข้อผิดพลาดกำลังสองที่เกิดขึ้นระหว่าง Yที่คาดการณ์ และ Yi< /แข็งแกร่ง>.
เราคำนวณ MSE โดยใช้สมการเชิงเส้นอย่างง่าย y=mx+b:

การไล่ระดับสีแบบไล่ระดับสำหรับการถดถอยเชิงเส้น
Gradient Descent เป็นหนึ่งในอัลกอริธึมการปรับให้เหมาะสมที่ปรับฟังก์ชันต้นทุนให้เหมาะสม (ฟังก์ชันวัตถุประสงค์) เพื่อให้ได้โซลูชันขั้นต่ำที่เหมาะสมที่สุด ในการค้นหาโซลูชันที่เหมาะสมที่สุด เราจำเป็นต้องลดฟังก์ชันต้นทุน (MSE) สำหรับจุดข้อมูลทั้งหมด ซึ่งทำได้โดยการอัพเดตค่าของ B0 และ B1 ซ้ำๆ จนกว่าเราจะได้คำตอบที่ดีที่สุด
โมเดลการถดถอยจะปรับอัลกอริทึมการไล่ระดับสีให้เหมาะสมเพื่ออัปเดตค่าสัมประสิทธิ์ของเส้นโดยการลดฟังก์ชันต้นทุนโดยการสุ่มเลือกค่าสัมประสิทธิ์ จากนั้นจึงอัปเดตค่าซ้ำๆ เพื่อให้ได้ฟังก์ชันต้นทุนขั้นต่ำ

การวัดผลการประเมินสำหรับการถดถอยเชิงเส้น
จุดแข็งของแบบจำลองการถดถอยเชิงเส้นสามารถประเมินได้โดยใช้ตัวชี้วัดการประเมินต่างๆ ตัวชี้วัดการประเมินเหล่านี้มักจะเป็นตัววัดว่าโมเดลสร้างผลลัพธ์ที่สังเกตได้ดีเพียงใด
ตัวชี้วัดที่ใช้มากที่สุดคือ
- ค่าสัมประสิทธิ์การหาค่าหรือ R-Squared (R2)
- ข้อผิดพลาด Root Mean Squared (RSME) และข้อผิดพลาดมาตรฐานที่เหลือ (RSE)
ค่าสัมประสิทธิ์การหาค่าหรือ R-Squared (R2)
R-Squared คือตัวเลขที่อธิบายจำนวนความแปรผันที่แบบจำลองที่พัฒนาขึ้นอธิบาย/บันทึกได้ โดยจะอยู่ระหว่าง 0 และ 1 เสมอ โดยรวมแล้ว ยิ่งค่า R-squared สูงเท่าใด โมเดลก็จะเหมาะกับข้อมูลมากขึ้นเท่านั้น
ในทางคณิตศาสตร์มันสามารถแสดงเป็น
R^2 = 1 — ( RSS/TSS )
- ผลรวมที่เหลือของกำลังสอง (RSS) หมายถึงผลรวมของกำลังสองของส่วนที่เหลือสำหรับแต่ละจุดข้อมูลในพล็อต/ข้อมูล เป็นการวัดความแตกต่างระหว่างผลลัพธ์ที่คาดหวังและผลลัพธ์ที่สังเกตได้จริง

ผลรวมกำลังสองทั้งหมด (TSS) หมายถึงผลรวมของข้อผิดพลาดของจุดข้อมูลจากค่าเฉลี่ยของตัวแปรตอบสนอง
ความสำคัญของ R-squared แสดงโดยตัวเลขต่อไปนี้

ข้อผิดพลาด Root Mean Squared
ค่าคลาดเคลื่อนกำลังสองเฉลี่ยของรากคือรากที่สองของความแปรปรวนของค่าคงเหลือ โดยระบุความพอดีที่แน่นอนของแบบจำลองกับข้อมูล เช่น จุดข้อมูลที่สังเกตได้ใกล้กับค่าที่คาดการณ์ไว้เพียงใด ในทางคณิตศาสตร์มันสามารถแสดงเป็น

เพื่อให้การประมาณค่านี้เป็นกลาง จะต้องหารผลรวมของส่วนที่เหลือยกกำลังสองด้วย ระดับความเป็นอิสระ แทนที่จะหารด้วยจำนวนจุดข้อมูลทั้งหมดในแบบจำลอง จากนั้นคำนี้จึงเรียกว่า ข้อผิดพลาดมาตรฐานคงเหลือ (RSE) ในทางคณิตศาสตร์มันสามารถแสดงเป็น

R-squared เป็นตัววัดที่ดีกว่า RSME เนื่องจากค่าของ Root Mean Squared Error ขึ้นอยู่กับหน่วยของตัวแปร (กล่าวคือ ไม่ใช่การวัดแบบมาตรฐาน) ค่านี้สามารถเปลี่ยนแปลงได้ตามการเปลี่ยนแปลงในหน่วยของตัวแปร
สมมติฐานของการถดถอยเชิงเส้น
การถดถอยเป็นแนวทางแบบพาราเมตริก ซึ่งหมายความว่าเป็นการตั้งสมมติฐานเกี่ยวกับข้อมูลเพื่อวัตถุประสงค์ในการวิเคราะห์ เพื่อให้การวิเคราะห์การถดถอยประสบความสำเร็จ จำเป็นต้องตรวจสอบสมมติฐานต่อไปนี้
- ความเป็นเชิงเส้นของส่วนที่เหลือ: ต้องมีความสัมพันธ์เชิงเส้นตรงระหว่างตัวแปรตามและตัวแปรอิสระ

2. ความเป็นอิสระของสิ่งตกค้าง:เงื่อนไขข้อผิดพลาดไม่ควรขึ้นอยู่กับกัน (เช่นในข้อมูลอนุกรมเวลาซึ่งค่าถัดไปขึ้นอยู่กับค่าก่อนหน้า) ไม่ควรมีความสัมพันธ์กันระหว่างเงื่อนไขคงเหลือ การไม่มีปรากฏการณ์นี้เรียกว่า ความสัมพันธ์อัตโนมัติ
ไม่ควรมีรูปแบบที่มองเห็นได้ในเงื่อนไขข้อผิดพลาด

<แข็งแกร่ง>3. การกระจายตัวของสารตกค้างตามปกติ: ค่าเฉลี่ยของสารตกค้างควรเป็นไปตามการแจกแจงแบบปกติโดยมีค่าเฉลี่ยเท่ากับศูนย์หรือใกล้กับศูนย์ ซึ่งทำเพื่อตรวจสอบว่าบรรทัดที่เลือกนั้นเป็นบรรทัดที่เหมาะสมที่สุดจริงหรือไม่
หากเงื่อนไขข้อผิดพลาดไม่กระจายตามปกติ แสดงว่ายังมีจุดข้อมูลที่ผิดปกติบางประการที่ต้องศึกษาอย่างใกล้ชิด สร้างโมเดลที่ดีขึ้น

<แข็งแกร่ง>4. ความแปรปรวนที่เท่ากันของค่าคงเหลือ: เงื่อนไขข้อผิดพลาดต้องมีความแปรปรวนคงที่ ปรากฏการณ์นี้เรียกว่า การรักร่วมเพศ
การมีอยู่ของความแปรปรวนที่ไม่คงที่ในเงื่อนไขของข้อผิดพลาดเรียกว่า Heteroscedasticity โดยทั่วไป ความแปรปรวนที่ไม่คงที่จะเกิดขึ้นเมื่อมี ค่าผิดปกติหรือค่าเลเวอเรจที่รุนแรง

ในบทความถัดไป เราจะใช้การถดถอยเชิงเส้นกับชุดข้อมูลของเรา
หากคุณพบบทความนี้ แสดงความขอบคุณด้วยการกดไลค์และแชร์บทความนี้