Ini adalah bagian kedua dari seri Scikit-learn, yaitu sebagai berikut:
- Bagian 1 — Pendahuluan
- Bagian 2 — Pembelajaran yang Diawasi di Scikit-Learn (artikel ini)
- Bagian 3 — Pembelajaran Tanpa Pengawasan di Scikit-Learn
Tautan ke bagian satu : https://medium.com/@deepanshugaur1998/scikit-learn-part-1-introduction-fa05b19b76f1
Tautan ke bagian ketiga : https://medium.com/@deepanshugaur1998/scikit-learn-beginners-part-3-6fb05798acb1
Pembelajaran yang Diawasi Dalam Scikit-Learn
Halo lagi !
Rekap Pembelajaran yang Diawasi :

T. Apa yang dimaksud dengan pembelajaran yang diawasi?
Dalam pembelajaran mesin, ini adalah jenis sistem yang menyediakan data masukan dan keluaran yang diinginkan. Data masukan dan keluaran diberi label untuk klasifikasi guna memberikan dasar pembelajaran untuk prediksi data di masa depan.

Sekarang, seperti pada bagian sebelumnya dari seri ini, kita telah melihat ikhtisar tentang apa yang ditawarkan oleh scikit learn dalam hal pembelajaran yang diawasi, tetapi dalam kali ini kita akan memahami bagaimana kita memulai dengan perpustakaan yang canggih ini.
Memulai…..
mari kita perhatikan contoh model regresi linier sederhana :
Tujuan matematis model ini adalah untuk meminimalkan jumlah sisa kuadrat antara respons yang diamati dalam kumpulan data, dan hasil yang diprediksi dengan pendekatan linier.

from sklearn.linear_model import LinearRegression #import statement clf=LinearRegression() #we created a classifier from an object named LinearRegression. clf.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2]) #fitting a classifier on a data clf.coef_ # calculated the slope OUTPUT : array([ 0.5, 0.5])
Seperti yang Anda lihat, hanya ada kode kecil yang dapat membantu Anda memulai dengan algoritma luar biasa ini. Luar biasa bukan? Anda bahkan dapat mencoba prediksi pada set pengujian dengan menggunakan fungsi '.pred'.
Untuk pemahaman lebih mendalam tentang model linier ini, pertimbangkan untuk mencoba sendiri dengan mengambil contoh.
Contoh mudahnya dapat ditemukan di sini :
Mendukung Mesin Vektor Di Sklearn
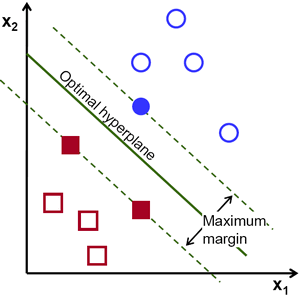
Ikuti kode di bawah ini untuk memulai svm di scikit-learn :
from sklearn import svm X = [[0, 0], [1, 1]] # dataset y = [0, 1] clf = svm.SVC() # classifier is created clf.fit(X, y) # fitting classifier on dataset OUTPUT : SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
Parameter yang Anda lihat dalam tanda kurung dapat diubah sesuai dengan kumpulan data yang diberikan kepada Anda.
Setelah Anda merasa nyaman menulis kode yang disebutkan di atas, coba sendiri dengan mengubah parameternya.
clf.predict([[1., 0.]]) # predicting values OUTPUT : array([1])
Penurunan Gradien Stokastik Di Sklearn

Algoritma Stochastic Gradient Descent adalah algoritma sederhana yang digunakan dalam pembelajaran diskriminatif pengklasifikasi linier pada kumpulan data besar dan juga mudah disesuaikan dengannya.
Kode :
from sklearn.linear_model import SGDClassifier
X = [[0., 0.], [1., 1.]]
y = [0, 1]
clf = SGDClassifier(loss=”hinge”, penalty=”l2") #hyperparameters
clf.fit(X, y)
OUTPUT : SGDClassifier(alpha=0.0001, average=False, class_weight=None, epsilon=0.1,
eta0=0.0, fit_intercept=True, l1_ratio=0.15,
learning_rate='optimal', loss='hinge', max_iter=5, n_iter=None,
n_jobs=1, penalty='l2', power_t=0.5, random_state=None,
shuffle=True, tol=None, verbose=0, warm_start=False)
Naif Bayes Di Sklearn

Pengklasifikasi Naive Bayes menghitung probabilitas untuk setiap faktor. Kemudian ia memilih hasil dengan probabilitas tertinggi.
Pengklasifikasi ini mengasumsikan fitur-fiturnya independen. Oleh karena itu, kata 'naif' digunakan.
Ini adalah salah satu algoritma paling umum dalam pembelajaran mesin.
Kode :
from sklearn import datasets iris = datasets.load_iris() # loading the dataset from sklearn.naive_bayes import GaussianNB gnb = GaussianNB() y_pred = gnb.fit(iris.data, iris.target).predict(iris.data) #fitting and predicting on same line. OUTPUT : [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
Regresi Pohon Keputusan di Sklearn

Pohon Keputusan adalah jenis lain dari algoritme pembelajaran mesin terawasi yang datanya terus dipecah berdasarkan parameter tertentu.
Semakin banyak data, semakin akurat modelnya.
Pohon keputusan adalah salah satu algoritme yang paling banyak digunakan dari semua algoritme pembelajaran yang diawasi dan menemukan penerapan besar di industri.

Kode :
from sklearn import tree X = [[0, 0], [1, 1]] Y = [0, 1] clf = tree.DecisionTreeClassifier() clf = clf.fit(X, Y) clf.predict([[2., 3.]]) OUTPUT : array([1])
Metode Ensemble Dalam SkLearn
Ini berisi metode mengantongi dan hutan acak.
Hutan Acak

Algoritme pembelajaran mesin canggih lainnya yang menghasilkan hasil luar biasa bahkan tanpa penyetelan hyper-parameter.
Ini juga merupakan salah satu algoritma yang paling banyak digunakan, karena kesederhanaannya dan fakta bahwa ia dapat digunakan untuk tugas klasifikasi dan regresi.
Kode :
from sklearn.ensemble import RandomForestClassifier X = [[0, 0], [1, 1]] Y = [0, 1] clf = RandomForestClassifier(n_estimators=10) clf = clf.fit(X, Y) pred = clf.predict([[2., 3.]]) print(pred) OUTPUT : [1]
Apa yang telah kita pelajari?
Sekarang kita telah mempelajari cara mengimplementasikan setiap algoritme yang diawasi menggunakan scikit learn.
Masih banyak fitur yang dimiliki setiap algoritme dalam scikit learn yang hanya dapat dikuasai dengan berlatih.
Jadi, berhentilah membuang-buang waktu dan pikiran Anda langsung ke dokumentasi resmi scikit learn untuk algoritma yang diawasi dan pastikan Anda memahami setiap algoritma secara matematis serta dengan berlatih pada kumpulan data yang berbeda.
Tautan :
http://scikit-learn.org/stable /supervised_learning.html
Catatan : Bagian selanjutnya dari seri ini akan membahas pembelajaran tanpa pengawasan, jadi pastikan Anda tidak melewatkannya.