BAGAIMANA KITA MENDEFINISIKANNYA?
Regresi linier adalah jenis analisis statistik yang digunakan untuk memprediksi hubungan antara dua variabel. Ini mengasumsikan hubungan linier antara variabel independen dan variabel dependen, dan bertujuan untuk menemukan garis yang paling sesuai untuk menggambarkan hubungan tersebut.
Regresi linier umumnya digunakan di banyak bidang, termasuk ekonomi, keuangan, dan ilmu sosial, untuk menganalisis dan memprediksi tren data.
REGRESI LINEAR SEDERHANA
Dalam regresi linier sederhana terdapat satu variabel bebas dan satu variabel terikat. Model memperkirakan kemiringan dan perpotongan garis yang paling sesuai, yang mewakili hubungan antar variabel. Kemiringan mewakili perubahan variabel dependen untuk setiap satuan perubahan variabel independen, sedangkan intersep mewakili nilai prediksi variabel dependen ketika variabel independen bernilai nol.
Regresi linier menunjukkan hubungan linier antara variabel bebas (prediktor) yaitu sumbu X dan variabel terikat (output) yaitu sumbu Y, yang disebut regresi linier. Jika terdapat satu variabel masukan X(variabel bebas), regresi linier tersebut disebut regresi linier sederhana.

BAGAIMANA MENGHITUNG GARIS FIT TERBAIK?
Untuk menghitung regresi linier garis paling cocok menggunakan bentuk perpotongan kemiringan tradisional yang diberikan di bawah ini
Yi = β0 + β1*Xi
dimana Yi = Variabel terikat, β0 = konstanta/Perpotongan, β1 = Kemiringan/Perpotongan, Xi = Variabel bebas.
Algoritma ini menjelaskan hubungan linier antara variabel terikat (output) y dan variabel bebas (prediktor) X dengan menggunakan garis lurus Y= B0 + B1* X.
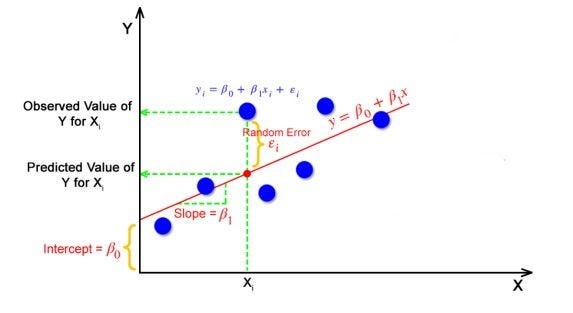
Dalam regresi, selisih antara nilai observasi variabel terikat (Yi) dan nilai prediksi (prediksi) disebut residu.
εi = Ydiprediksi — Yi
di mana Ydiprediksi = B0 + B1*Xi
Fungsi Biaya untuk Regresi Linier
Fungsi biaya membantu menentukan nilai optimal untuk B0 dan B1, yang memberikan garis paling sesuai untuk titik data.
Dalam Regresi Linier, umumnya digunakan fungsi biaya Mean Squared Error (MSE), yaitu rata-rata kesalahan kuadrat yang terjadi antara Yyang diprediksi dan Yi.
Kami menghitung MSE menggunakan persamaan linier sederhana y=mx+b:

Penurunan Gradien untuk Regresi Linier
Gradient Descent merupakan salah satu algoritma optimasi yang mengoptimalkan fungsi biaya (fungsi tujuan) untuk mencapai solusi minimal optimal. Untuk menemukan solusi optimal kita perlu mengurangi fungsi biaya (MSE) untuk semua titik data. Hal ini dilakukan dengan memperbarui nilai B0 dan B1 secara iteratif hingga diperoleh solusi optimal.
Model regresi mengoptimalkan algoritma penurunan gradien untuk memperbarui koefisien garis dengan mengurangi fungsi biaya dengan memilih nilai koefisien secara acak dan kemudian memperbarui nilai secara berulang untuk mencapai fungsi biaya minimum.

Metrik Evaluasi untuk Regresi Linier
Kekuatan model regresi linier apa pun dapat dinilai menggunakan berbagai metrik evaluasi. Metrik evaluasi ini biasanya memberikan ukuran seberapa baik keluaran yang diamati dihasilkan oleh model.
Metrik yang paling banyak digunakan adalah,
- Koefisien determinasi atau R-Squared (R2)
- Root Mean Squared Error (RSME) dan Residual Standard Error (RSE)
Koefisien determinasi atau R-Squared (R2)
R-Squared merupakan angka yang menjelaskan besarnya variasi yang dijelaskan/ditangkap oleh model yang dikembangkan. Itu selalu berkisar antara 0 & 1 . Secara keseluruhan, semakin tinggi nilai R-squared, semakin baik model tersebut cocok dengan data.
Secara matematis dapat direpresentasikan sebagai,
R^2 = 1 — ( RSS/TSS )
- Jumlah Sisa Kuadrat (RSS) didefinisikan sebagai jumlah kuadrat dari sisa untuk setiap titik data dalam plot/data. Ini adalah ukuran perbedaan antara keluaran yang diharapkan dan keluaran aktual yang diamati.

Jumlah Total Kuadrat (TSS) didefinisikan sebagai jumlah kesalahan titik data dari rata-rata variabel respons.
Signifikansi R-squared ditunjukkan oleh gambar berikut,

Kesalahan Root Mean Squared
Root Mean Squared Error adalah akar kuadrat dari varians residu. Ini menentukan kesesuaian absolut model dengan data, yaitu seberapa dekat titik data yang diamati dengan nilai prediksi. Secara matematis dapat direpresentasikan sebagai,

Agar estimasi ini tidak bias, jumlah residu kuadrat harus dibagi dengan derajat kebebasan, bukan dengan jumlah total titik data dalam model. Istilah ini kemudian disebut Kesalahan Standar Residu (RSE). Secara matematis dapat direpresentasikan sebagai,

R-squared adalah ukuran yang lebih baik daripada RSME. Karena nilai Root Mean Squared Error bergantung pada satuan variabel (yaitu bukan ukuran yang dinormalisasi), maka nilai tersebut dapat berubah seiring dengan perubahan satuan variabel.
Asumsi Regresi Linier
Regresi merupakan pendekatan parametrik, artinya membuat asumsi tentang data untuk tujuan analisis. Agar analisis regresi berhasil, penting untuk memvalidasi asumsi berikut.
- Linearitas residu: Harus ada hubungan linier antara variabel terikat dan variabel bebas.

2. Independensi residu:Istilah kesalahan tidak boleh bergantung satu sama lain (seperti pada data deret waktu di mana nilai berikutnya bergantung pada nilai sebelumnya). Seharusnya tidak ada korelasi antara sisa istilah. Tidak adanya fenomena ini dikenal sebagai Autokorelasi.
Seharusnya tidak ada pola yang terlihat dalam istilah kesalahan.

Jika suku kesalahan tidak terdistribusi secara normal, menunjukkan bahwa ada beberapa titik data yang tidak biasa yang harus dipelajari dengan cermat untuk membuat model yang lebih baik.

Adanya varians yang tidak konstan dalam istilah kesalahan disebut sebagai Heteroskedastisitas. Umumnya, varians non-konstan muncul ketika terdapat outlier atau nilai leverage ekstrem.

Pada artikel selanjutnya kita akan menerapkan regresi linier pada kumpulan data kita.
Jika Anda menemukan artikel ini, tunjukkan apresiasi Anda dengan menyukai dan membagikan artikel ini.