Это вторая часть серии Scikit-learn, которая выглядит следующим образом:
- Часть 1 - Введение
- Часть 2 - Обучение с учителем в Scikit-Learn (эта статья)
- Часть 3 - Обучение без учителя в Scikit-Learn
Ссылка на первую часть: https://medium.com/@deepanshugaur1998/scikit-learn-part-1-introduction-fa05b19b76f1
Ссылка на третью часть: https://medium.com/@deepanshugaur1998/scikit-learn-beginners-part-3-6fb05798acb1
Обучение с учителем в Scikit-Learn
И снова здравствуйте !
Резюме к контролируемому обучению:

В. Что такое обучение с учителем?
В машинном обучении это тип системы, в которой предоставляются как входные, так и желаемые выходные данные. Входные и выходные данные помечаются для классификации, чтобы обеспечить обучающую основу для будущего прогнозирования данных.

Теперь, как и в предыдущей части этой серии, мы уже видели обзор того, что предлагает scikit learn с точки зрения контролируемого обучения, но в этом мы поймем, как начать работу с этой мощной библиотекой.
Начало работы…
давайте рассмотрим пример простой модели линейной регрессии:
Математическая цель этой модели - минимизировать остаточную сумму квадратов между наблюдаемыми ответами в наборе данных и результатами, предсказанными линейным приближением.

from sklearn.linear_model import LinearRegression #import statement clf=LinearRegression() #we created a classifier from an object named LinearRegression. clf.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2]) #fitting a classifier on a data clf.coef_ # calculated the slope OUTPUT : array([ 0.5, 0.5])
Как видите, есть только небольшой код, который поможет вам начать работу с этим удивительным алгоритмом. Разве это не потрясающе? Вы даже можете попробовать сделать прогноз на тестовом наборе с помощью функции «.pred».
Для более глубокого понимания этой линейной модели попробуйте сами на примере.
Простой пример можно найти здесь:
Машины опорных векторов в Sklearn
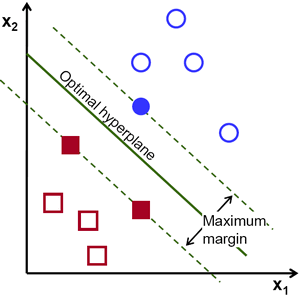
Следуйте приведенному ниже коду, чтобы начать работу с svm в scikit-learn:
from sklearn import svm X = [[0, 0], [1, 1]] # dataset y = [0, 1] clf = svm.SVC() # classifier is created clf.fit(X, y) # fitting classifier on dataset OUTPUT : SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
Параметры, которые вы видите в скобках, можно изменить в соответствии с предоставленным вам набором данных.
Как только вы научитесь писать вышеупомянутый код, попробуйте сами, настроив параметры.
clf.predict([[1., 0.]]) # predicting values OUTPUT : array([1])
Стохастический градиентный спуск в Sklearn

Алгоритм стохастического градиентного спуска - это простой алгоритм, который используется для дискриминантного обучения линейных классификаторов на большом наборе данных, а также легко вписывается в него.
Код:
from sklearn.linear_model import SGDClassifier
X = [[0., 0.], [1., 1.]]
y = [0, 1]
clf = SGDClassifier(loss=”hinge”, penalty=”l2") #hyperparameters
clf.fit(X, y)
OUTPUT : SGDClassifier(alpha=0.0001, average=False, class_weight=None, epsilon=0.1,
eta0=0.0, fit_intercept=True, l1_ratio=0.15,
learning_rate='optimal', loss='hinge', max_iter=5, n_iter=None,
n_jobs=1, penalty='l2', power_t=0.5, random_state=None,
shuffle=True, tol=None, verbose=0, warm_start=False)
Наивный байесовский в Sklearn

Наивный байесовский классификатор вычисляет вероятности для каждого фактора. Затем он выбирает результат с наибольшей вероятностью.
Этот классификатор предполагает, что функции независимы. Таким образом, используется слово «наивный».
Это один из самых распространенных алгоритмов в машинном обучении.
Код:
from sklearn import datasets iris = datasets.load_iris() # loading the dataset from sklearn.naive_bayes import GaussianNB gnb = GaussianNB() y_pred = gnb.fit(iris.data, iris.target).predict(iris.data) #fitting and predicting on same line. OUTPUT : [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
Регрессия дерева решений в Sklearn

Деревья решений - это еще один тип контролируемого алгоритма машинного обучения, в котором данные непрерывно разделяются в соответствии с определенным параметром.
Чем больше данных, тем важнее точность модели.
Деревья решений - один из наиболее часто используемых алгоритмов. из всех контролируемых алгоритмов обучения и находит огромное применение в отрасли.

Код:
from sklearn import tree X = [[0, 0], [1, 1]] Y = [0, 1] clf = tree.DecisionTreeClassifier() clf = clf.fit(X, Y) clf.predict([[2., 3.]]) OUTPUT : array([1])
Ансамблевые методы в SkLearn
Он содержит методы упаковки и случайные леса.
Случайные леса

Еще один мощный алгоритм машинного обучения, который дает отличный результат даже без настройки гиперпараметров.
Это также один из наиболее часто используемых алгоритмов из-за его простоты и того факта, что он может использоваться как для задач классификации, так и для задач регрессии.
Код:
from sklearn.ensemble import RandomForestClassifier X = [[0, 0], [1, 1]] Y = [0, 1] clf = RandomForestClassifier(n_estimators=10) clf = clf.fit(X, Y) pred = clf.predict([[2., 3.]]) print(pred) OUTPUT : [1]
Что мы узнали?
К настоящему времени мы узнали, как реализовать каждый контролируемый алгоритм с помощью scikit learn.
Тем не менее, у каждого алгоритма есть много функций в scikit learn, которые можно освоить только на практике.
Так что хватит тратить свое время и голову прямо на официальную документацию scikit learn для контролируемых алгоритмов и убедитесь, что вы понимаете каждый алгоритм математически, а также практикуетесь с разными наборами данных.
Ссылка:
http://scikit-learn.org/stable /supervised_learning.html
Примечание. Следующая часть этой серии будет посвящена обучению без учителя, поэтому не пропустите это.